
Background
rsync is an algorithm for efficient remote update of files over low bandwidth network link.
Definitions
- S (source) – the process at the end that has access to the latest version of a file.
- T (target) – the process at the end that has access to a version of a file that is older than the version S has.
Requirements
- Sync changes between target file T that has older version of a source file S.
- Minimize the network traffic for the synchronization.
Implementation
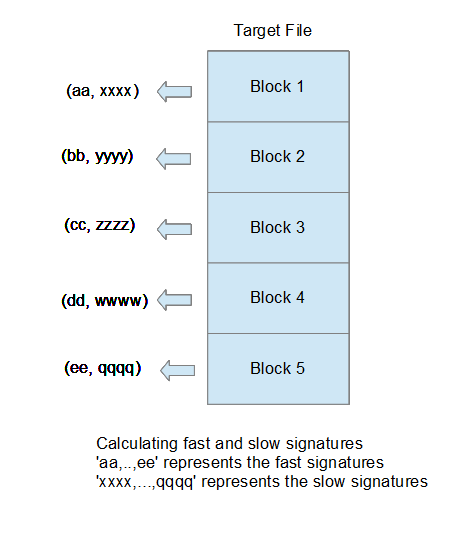
- T (the target) divides the file into blocks with fixed size L.
- For each block, T calculates a signature that is fast to calculate but not unique.
- For each block, T calculates a signature that is slow to calculate but unique.
- T sends S a list of pairs with fast and slow signatures for each block.
- S starts checking its first block.
- T created a temporary empty file X that will replace its current file with the version from S side.
- S calculate the fast signature for the block, if it is not equal to any of T fast signatures then S sends the first byte to T and T append this byte to file X. if the fast signature is equal, then S calculate the slow signature of the block and compare it to the matching slow signature. if the two signatures are equals then S sends T the id of the block. T append the block from its local copy via block id. if the slow signature is not equal then S will send the first byte to T.
- The next block S will check will be the one starting in the next byte if the previous block did not match or the one starting in an offset of block size if the previous block matched. S may need to calculate the fast signature to every possible block (i.e. blocks generated from the previous block by shifting one byte at a time, starting from the first block and ending in the last) – so rsync is using a method similar to Adler checksum that can be calculated efficiently in iterations based on previous block signature plus small number of steps.
- repeat steps 7-8 until S reach its end.



Reference:
- Andrew Tridgell, “Efficient Algorithms for Sorting and Synchronization” , https://rsync.samba.org/~tridge/phd_thesis.pdf




 .
.