
Short story
Recently, I remembered that when I was a student, I read about Huffman coding which is a clever compressing algorithm and ever since wanted to implement it but did not found a chance. Last week – I finally did it. To test my implementation – I took a 160 KB file containing the text of ‘Alice in Wonderland’ book and compressed it using my Huffman implementation down to 94 KB binary file. Hurrah!
What is prefix code?
There are many ways to map a set of characters to a set of bits and so represent text in bits. For example ANSI is a map that takes the latin alphabet and map each character to a byte. When you get a file in ANSI encoding you know that you need to scan the file reading sets of 8 bits (one byte) and translate the byte to a character. Giving the same number of bits to represent each character simplifies decoding as you only need to read fix number of bits and translate each to relevant character but is not optimal from size perspective as often used characters get the same representation as rarely used characters.
Some encoding techniques maps characters to bits so that different characters are mapped to list of bits with different size.When more often used characters are mapped to a smaller list of bits than you expect the encode file to take less space than one encode in ANSI (more on how to measure space efficiency later in the post). The challenge with this approach is to know when you are decoding a list of bits when one character representations ends and another begins. One solution for this is to use some list of bits to represent a marker between list of bits representing different characters, and another solution is to use binary trees like Huffman tree (more on this later in the post.)
prefix code is a type of code that let you decode the encoded text without special marker. for example, the map {a=0, b=10, c=11} is a prefix code as no marker is needed for decryption of any string. If you have ‘000101011’ then it is clear when one list of bits for character ends and another begins you translate it directly to ‘aaabbc’. a counter example, the map {a=0, b=1, c=11} is not prefix code as the string ‘111’ can be translated to ‘bbb’ or ‘bc’ i.e., we need some separator marker between list of bits in this code.
How to measure coding efficiency?
If the coding is represented by a map from a character 


The code efficiency is calculated by 
Every prefix code can also be represented as a binary tree where each edge is marked as ‘0’ or ‘1’ and the leaf are marked with a character so the list of edges to a leaf represent the character’s code. Here is a picture that show this idea:
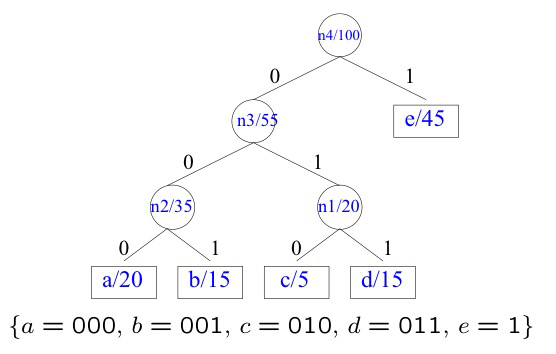
The depth of a leaf is actually the size of a character prefix code and so this representation provide an alternative to the efficient of the code in the language of trees i.e.,
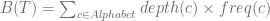

How does Huffman encoding work?
Here is the algorithm to build Huffman tree:
- Create a node for each character with its frequency and insert it to a list.
- Remove from the list the two nodes with minimum frequencies. Then create a tree where the two nodes are “siblings” leafs and their parent is marked with the sum of their frequencies (the root has no character associated to it).
- add the root node into the list. The list now is shorter by one element.
- goto 3 until a single node remains in the list. This node will be the root to the Huffman tree.
Example:
Let look at a text with 20 ‘a’, 15 ‘b’, 5 ‘c’, 15 ‘d’, 45 ‘e’.
Step 1 says we will prepare a list {a/20 , b/15, c/5, d/15, e/45}.
Iteration 1:
Step 2 says we need to choose two minimum nodes e.g., ‘c’ and ‘d’ (we could also take the pairs ‘c’ and ‘b’ as the minimum frequencies nodes.) and create a tree:

we give this node alias ‘n1’ for consistent labeling of nodes but there is no use of this value. note that its frequency is 20 = 5 + 15.
step 3 says that we will add ‘n1’ to the list, ending up with the list {a/20, n1/20, b/15, e/45}.
Iteration 2:
Step 2, similarly as we did above, we choose ‘a’ and ‘b’ and produce a new node n2 and a tree:
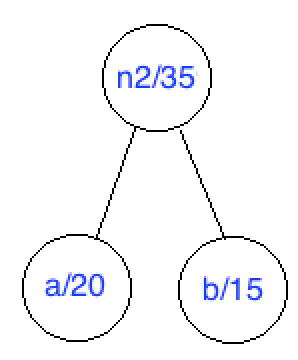
step 3, the list end up looking like this {n2/35, n1/20, e/45}.
Iteration 3
step 2, combines n2/35 and n1/20 under the new node n3/55:

step 3, the list end up looking like this {n3/55, e/45}.
It should be clear that after the 4th iteration we will end up with the Huffman tree shown in the previous section.
Why Huffman encoding is optimal? – a mathematical proof
In our context, optimal encoding means that if you take a fix alphabet with known frequencies then the Huffman code will have the minimum code efficiency value as calculated above when compared to all possible prefix codes available for this alphabet (with the same frequencies).
Lemma 1: Consider the two letters, x and y with the smallest frequencies. Then there is an optimal tree in which these two letters are sibling leaves in the tree in the lowest level.
Proof: First, we notice that an optimal tree T must be full in the sense that all internal nodes should have two “child” nodes – otherwise if there is an internal node P with a single child node Q then we could remove P from the tree and set Q (and all its sub tree) in P place – which will reduce the depth value of all the nodes under Q by one and so reduce B(T) value in contrast to the fact that B(T) has minimum value.
Next, let T be an optimum prefix code tree, and let b and c be two siblings at the maximum depth of the tree (must exist because T is full). Since x and y have the two smallest frequencies it follows that 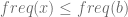
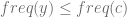
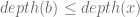

Now switch the positions of x and b in the tree resulting in a different tree T’ and see how the cost changes.
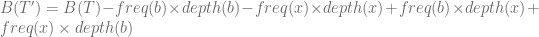
rearranging the left side of the equation,
![B(T')=B(T)- [(freq(x) - freq(b))\times (depth(x)-depth(b))] \le B(T)](https://s0.wp.com/latex.php?latex=B%28T%27%29%3DB%28T%29-+%5B%28freq%28x%29+-+freq%28b%29%29%5Ctimes+%28depth%28x%29-depth%28b%29%29%5D+%5Cle+B%28T%29&bg=ffffff&fg=5e5e5e&s=0&c=20201002)
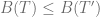
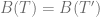
Repeating this argument by replacing y and c will result with the required optimal tree.
Q.E.D
Theorem: The Huffman coding has code efficiency which is lower than all prefix coding of this alphabet.
Proof: We will prove this by induction on the size of the alphabet.
Starting with an alphabet of size 2, Huffman encoding will generate a tree with one root and two leafs. it is obvious that this tree is the smallest one and so the coding efficiency of this tree is minimal.
Assume the theorem is true to all alphabets of size n-1 and we will prove that it is also true for all alphabet of size n.
Let A be an alphabet with n characters and let T be the optimal tree for A. T has two leafs ‘x’ and ‘y’ which are “siblings” with minimum frequencies due to Lemma 1. we will look at T’ which is constructed from T by removing the leafs ‘x’ and ‘y’. We can look at T’ as a prefix code for the A’ alphabet which is constructed from A by removing characters ‘x’ and ‘y’ and adding a new character ‘z’ which is their parent node in T. Any character requires a frequency associated with so we will set the frequency of ‘z’ to be 
We have
(1) 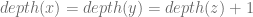

(2) 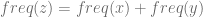
(3) 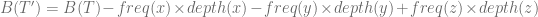
substituting 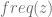
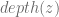
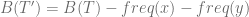
(4) 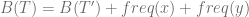
Let H’ be the Huffman tree for A’ . According to our assumption H’ is optimal and so
(5) 
Adding to H’ two leafs ‘x’ and ‘y’ under the parent ‘z’ will leave us with Huffman tree H for alphabet A.
This is true as the first step in building H according to the algorithm above is to add ‘x’ and ‘y’ under ‘z’, then remove from A the characters ‘x’ and ‘y’ and replace them by ‘z’ i.e., the rest of algorithm is building Huffman tree for A’ which is exactly H’ (I find this part of the proof to be the hardest part to grasp).
Following the same argument as we had for calculating 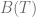
(6) 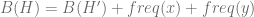
From (5) and (6) we get
(7) 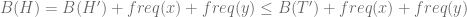
from (7) and (4) we get
(8) 
As T is an optimal tree, we also have
(9) 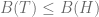
From (8) and (9) we get

This complete the induction proof.
Q.E.D
References
